")
")
Ați observat vreodată că uneori este nevoie de mult timp pentru ca calculatorul sau telefonul dvs. să încarce un site web sau o aplicație? Acest lucru se datorează faptului că datele trebuie să călătorească de pe dispozitivul dvs. la un server îndepărtat, unde sunt procesate și apoi trimise înapoi pe dispozitiv.
Ce este Edge-Fog-Cloud?
Edge-Fog-Cloud Computing este o nouă modalitate de procesare a datelor care ajută la a face acest proces mai rapid și mai eficient. Funcționează prin împărțirea activității de calcul între diferite straturi: stratul „Edge” sunt dispozitivele care sunt cele mai apropiate de tine, cum ar fi telefonul sau ceasul inteligent. Stratul de „Fog” este format din computere sau servere din apropiere care pot ajuta la procesarea datelor. Iar stratul „Cloud” este un grup de servere care sunt departe, dar au multă putere de procesare a datelor.
Împărțind munca în acest fel, Edge-Fog-Cloud Computing poate face ca aplicațiile și site-urile web să se încarce mai repede, deoarece datele nu trebuie să călătorească atât de departe. De asemenea, facilitează procesarea unor cantități mari de date în timp real, ceea ce poate fi util pentru aplicații precum mașinile cu conducere autonomă sau casele inteligente.
Pe scurt, Edge-Fog-Cloud Computing este o nouă modalitate de procesare a datelor care poate face dispozitivele noastre mai rapide și mai eficiente și este ceva despre care probabil că vom vedea mai multe în viitor!
Cum funcționează Edge-Fog-Cloud Computing?
Din punct de vedere tehnic și ingineresc, Edge-Fog-Cloud Computing este o nouă paradigmă în calcul care a apărut în ultimii ani. Este un model de calcul distribuit care combină punctele forte a trei modele de calcul diferite: Edge Computing, Fog Computing și Cloud Computing. Această abordare este concepută pentru a ajuta organizațiile să gestioneze mai bine cantitățile tot mai mari de date generate de dispozitive și sisteme, abordând în același timp probleme precum latența, securitatea și confidențialitatea.
Scopul Edge-Fog-Cloud Computing este de a oferi o arhitectură de calcul distribuită care poate gestiona eficient procesarea și analiza datelor la scară largă. În acest model, sarcinile de calcul sunt distribuite pe mai multe straturi, de la dispozitive de edge la noduri de fog la servere cloud. Combinând punctele forte ale acestor trei modele de calcul, Edge-Fog-Cloud Computing oferă o abordare flexibilă, scalabilă și rentabilă a calculului, care poate ajuta organizațiile să-și atingă obiectivele de afaceri mai eficient.
În secțiunile următoare, vom explica fiecare dintre cele trei componente ale Edge-Fog-Cloud Computing mai detaliat.
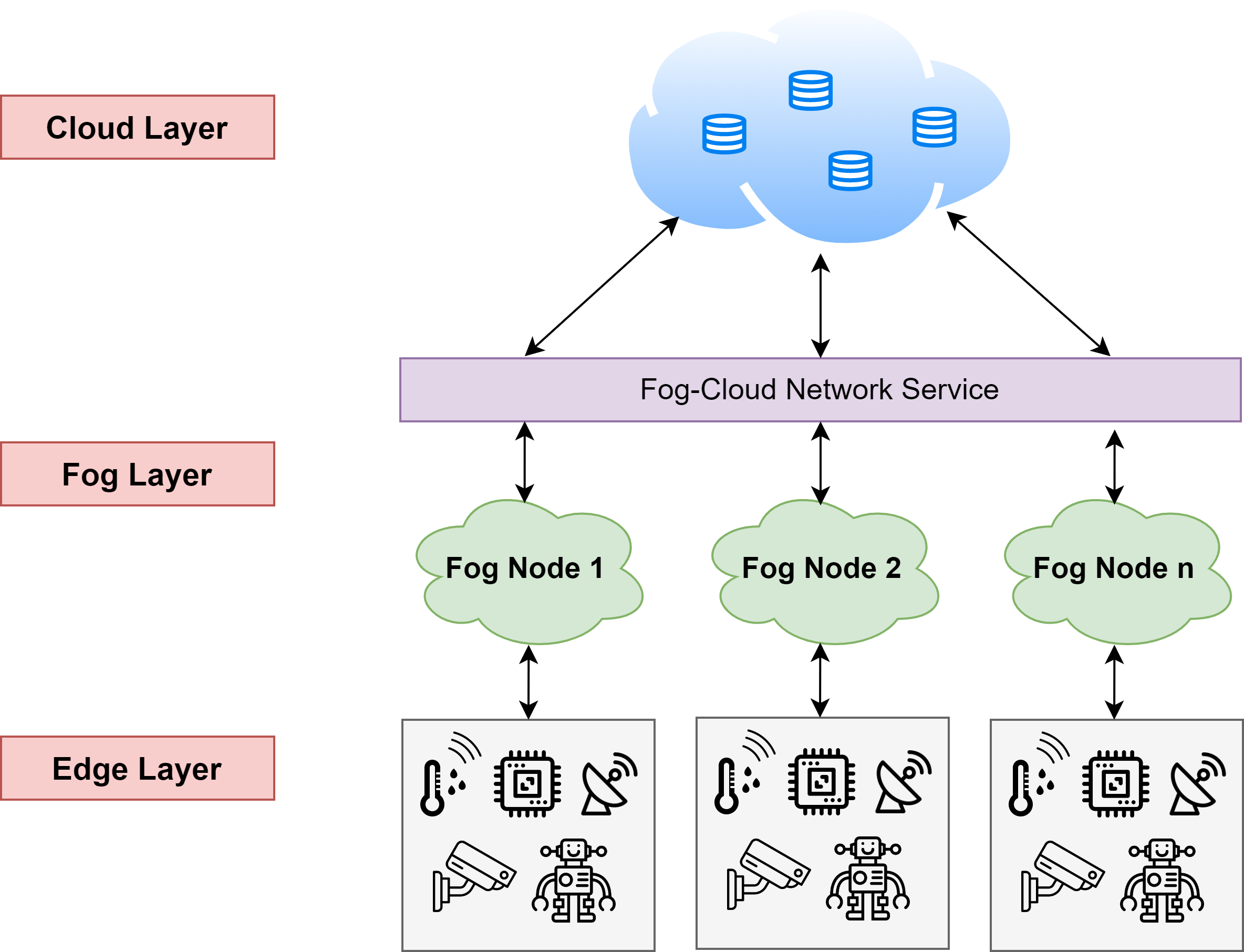
Arhitectura Edge-Fog-Cloud
1.Edge Computing:
Edge computing se referă la utilizarea resurselor și serviciilor de calcul care sunt situate mai aproape de utilizatorul final sau dispozitiv. Acest lucru este în contrast cu cloud computing tradițional, în care toate calculele sunt efectuate în centre de date centralizate. Cu edge computing, procesarea se face pe dispozitive precum smartphone-uri, dispozitive IoT sau routere de rețea, care sunt situate mai aproape de sursa de date. Acest lucru permite o procesare mai rapidă și reduce latența asociată cu trimiterea datelor către un Cloud centralizat. Edge computing este deosebit de util pentru aplicațiile care necesită procesarea și analiza în timp real a datelor, cum ar fi în IoT industrial sau vehicule autonome.
2. Fog Computing:
Fog computing extinde edge computing prin crearea unei ierarhii de resurse de calcul care oferă mai multă putere de procesare și capacitate de stocare. Nodurile de Fog sunt puncte intermediare între dispozitivele Edge și serverele Cloud care pot oferi capabilități suplimentare de procesare și stocare. Aceste noduri pot fi amplasate în echipamentele de rețea din apropiere sau la marginea rețelei, mai aproape de utilizatorul final. Fog computing poate ajuta la reducerea latenței, la îmbunătățirea securității și la furnizarea de scalabilitate și flexibilitate mai mari a resurselor de calcul.
3. Cloud Computing:
Cloud computing se referă la utilizarea serverelor de la distanță pentru stocarea, gestionarea și procesarea datelor. Cloud computing oferă resurse de stocare și de calcul practic nelimitate care pot fi accesate de oriunde cu o conexiune la internet. Serverele cloud sunt de obicei situate în centre de date care sunt departe de utilizatorul final. Cloud computing este util în special pentru aplicațiile care necesită procesare și analiză a datelor la scară largă, cum ar fi analiza big data sau învățarea automată.
Concluzii
Prin combinarea acestor trei modele de calcul, Edge-Fog-Cloud Computing oferă o arhitectură de calcul distribuită care poate gestiona eficient procesarea și analiza datelor la scară largă. În acest model, sarcinile de calcul sunt distribuite pe mai multe straturi, de la dispozitive Edge la noduri Fog la servere Cloud. Această abordare permite o procesare mai rapidă a datelor, o latență redusă și o fiabilitate îmbunătățită.
Edge-Fog-Cloud Computing, în ansamblu, oferă o soluție de calcul extrem de adaptabilă, ușor de extins și eficient din punct de vedere al costurilor, care poate ajuta companiile să își atingă obiectivele cu o eficiență mai mare.
Ce este Big Data? Spre deosebire de ce ar putea sugera numele, nu este vorba neapărat de fișiere mari sau despre cunoștințe complete despre un anumit domeniu. Dar, pentru a înțelege mai bine semnificația acestui termen important, mai întâi să înțelegem ce sunt exact Datele și cum pot fi acestea MARI.
Ce sunt Datele?
Spre deosebire de informații, care pot implica înțelegere asupra unui anumit lucru, datele pot fi privite ca o măsurare a ceva, o valoare care descrie starea într-un anumit moment, fără nici o informație despre cât de mare sau mică este această valoare. Așadar, informațiile ar putea fi privite ca o comparație a datelor cu anumite referințe pe o perioadă anume de timp.
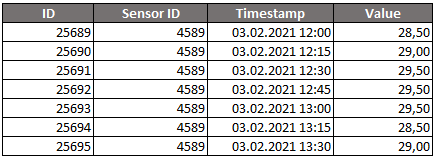
Să luăm cazul unui senzor de temperatură. Dacă îl plasăm într-un mediu necunoscut și obținem valoarea 32°C, aceasta este o valoare unică, o citire. Dar, ce putem învăța despre această valoare? Momentan nimic. Nu avem cu ce să comparăm valoarea, pentru a putea extrage informații utile de acolo. Nu știm în ce mediu funcționează acel senzor, care sunt valorile minime și maxime întâlnite acolo, sau valoarea medie a temperaturii.
Pentru a putea extrage informații despre mediul în sine, trebuie să folosim mai mulți senzori, plasați eficient, și trebuie să colectăm mai multe măsurători. Numărul de măsurători per unitate de timp se numește rezoluție, iar acest aspect este foarte important, deoarece pentru anumite aplicații s-ar putea să fie nevoie de o anumită rezoluție, suficient de mare, astfel încât mediul să se dezvăluie pe deplin.
Ce este Big Data?
Să ne imaginăm că avem de citit date de la mai mulți senzori dintr-o seră de legume. Pentru a înțelege mai bine condițiile de creștere a plantelor, sunt necesari mai multe tipuri de senzori, cum ar fi de temperatură, umiditate, nivel de iluminare și așa mai departe. Să presupunem că dispunem de 20 de astfel de senzori.
Suntem interesați să aflăm variația zilnică a tuturor senzorilor, așadar o rezoluție de 15 minute per citire ar trebui să fie potrivită. Aceasta înseamnă 96 de citiri per senzor pe zi, deci un total de 1920 de citiri zilnice per aplicație. Anual, dimensiunea bazei de date crește cu încă 700,000 de citiri. Volumul este deja copleșitor și crește exponențial pe măsură ce trece timpul. Aceasta explică ce este de fapt Big Data.
De ce este azi important Big Data?
Trăim într-o lume a informațiilor și suntem înconjurați de nenumărate sisteme care generează zilnic mulți petabiți de date. Colectarea și analiza acestor date este extrem de importantă în contextul optimizărilor ce pot fi aplicate pe sisteme, dar și în alte scopuri precum detectarea defectelor, securitatea cibernetică, detectarea intruziunilor, a fraudei și multe altele.
Concluzie
Un aspect important de remarcat este faptul că Big Data nu se limitează la Internet of Things (IoT), ci are multe alte aplicații și în alte domenii, cum ar fi serviciile bancare. Volumele uriașe de date sunt generate zilnic de fiecare sistem. De ce să nu folosim aceste date pentru a inspecta, depana și optimiza aceste sisteme?
Holisun poate oferi metodologii de Data Mining (analiză a datelor) precum și fluxuri de lucru complete ce permit analizarea, rezumarea de Big Data, precum și generarea de modele de învățare automată (Machine Learning) pe baza acestora. Cu astfel de modele se pot genera modele de Digital Twins, cu care se pot analiza sistemele chiar și din punctul de vedere al predicțiilor. Abordările de tip Big Data sunt implementate în unele dintre proiectele noastre de cercetare, cum ar fi BIECO, MUSNOMICS și SDK4ED.
De-a lungul istoriei, inteligența a fost definită în mai multe moduri: abilitatea de a înțelege matematica și a face calcule, de a rezolva probleme, înțelegerea idei de comunicație, cunoștința de sine, capacitatea de a învăța, și așa mai departe, la început în efortul de a stabili diferența dintre oameni și animale (în percepția de atunci, inteligența fiind una dintre principalele diferențe), iiar mai târziu pentru a înțelege viața per ansamblu.
Înțelegerea noastră actuală a inteligenței poate fi descrisă ca abilitatea de a percepe informații, de a păstra cunoștințele și chiar de a le aplica pentru adaptarea comportamentului (https://en.wikipedia.org/wiki/Intelligence). În acest sens, toată viața cunoscută este inteligentă, deoarece adaptările la mediile disponibile au însemnat schimbarea comportamentului pentru a supraviețui.
Inteligența artificială (sau IA/AI(eng)), pe de altă parte, are aplicații foarte diferite. De-a lungul istoriei încă scurte a lumii IT, informaticienii au început să dezvolte algoritmi pentru probleme matematice dificile, pentru care nu a fost conceput încă un algoritm stabilit. Astfel, abordările generalizate au venit în ajutor.
Tipuri de probleme
În matematică, există trei elemente clare care definesc în mod complet o problemă: input-ul, sau datele problemei, funcția obiectiv, sau modul de rezolvare a problemei (care poate fi sau nu oricât de complexă), și output-ul, sau rezultatul obținut.

În lumea Inteligenței Artificiale există în prezent două mari tipuri (sau clase) de probleme, care trebuie rezolvate într-un anume fel:
- Probleme pentru care cunoaștem rezultatul și datele de intrare, dar nu cunoaștem modul de calcul al acestor rezultate. Aici intră problemele de regresie, clasificare și altele.
- Probleme la care cunoaștem care sunt datele de intrare și o modalitate de a verifica dacă o soluție anume este bună, însă noi vrem să vedem ce combinație de valori de intrare (sau ordine a acestor valori) ne dă cea mai bună soluție la ieșire. Această problemă se numește optimizare și stă la baza a nenumărate aplicații ce le utilizăm zilnic, cum ar fi aplicațiile de generare a rutelor cele mai scurte între două puncte, internetul în sine și multe altele.
Inspirându-ne din natură, putem găsi două abordări majore, cel puțin câte una pentru fiecare tip de problemă:
- Algoritmi evolutivi, care utilizează concepte cum ar fi evoluția, genetica dar și alte abordări din lumea animală cum ar fi comportamentul coloniilor de furnici sau albine. Acești algoritmi sunt utilizați cu succes pentru optimizarea diferitelor funcții sau aplicații.
- Abordări de tip învățare automată (Machine Learning), care „învață” datele de intrare și găsesc moduri de a calcula ieșirile pe baza acestora.
Optimizare Evolutivă, Algoritmi Genetici
Din lumea optimizărilor, una dintre cele mai cunoscute clase de algoritmi sunt algoritmii evolutivi, în special Algoritmii Genetici (AG). Aceștia se folosesc de principiile evoluției, așa cum au fost formulate de Charles Darwin (încorporând și ultimele observații făcute de experți), pentru a genera cel puțin o soluție viabilă și apoi a o optimiza (îmbunătățirea unui anumit indicator de performanță). Putem aplica astfel de algoritmi în probleme unde dispunem de datele de intrare și avem o modalitate de a verifica dacă o soluție este potrivită sau nu, dar nu avem nici un mod de a calcula cea mai bună soluție.
De exemplu, să discutăm Problema Comis Voiajorului (în literatura de specialitate cunoscută ca TSP - Travelling Salesman Problem). Un comis voiajor dorește să viziteze mai multe orașe, dorind de asemenea să păstreze cheltuielile la un nivel cât mai scăzut posibil. O rută este secvența (sau ordinea) în care orașele sunt vizitate. Cea mai bună rută va fi ruta cu cel mai mic cost, unde costul poate fi: timpul, prețul total, distanța, sau orice altceva ne-ar interesa.
Într-o implementare a unui algoritm genetic, orice rută posibilă (candidat) este denumită un Individ. Fiecare oraș este o Genă din Cromozomul individului, iar ordinea acestor gene fiind ruta propusă. Algoritmul funcționează prin crearea unei populații de indivizi și aplicarea unui set de operatori: Selecție, Încrucișare și Mutație. Recent, alte aspecte sunt studiate și considerate ca operatori, cum ar fi: Supraviețuirea, Endogamia, Monogamia, etc.
Așa cum v-ar putea spune intuiția, algoritmii evolutivi funcționează prin modificarea graduală a unor părți din indivizi în cadrul unui set de soluții (populația), pentru a se vedea dacă rezultatele se îmbunătățesc. Așadar, nu avem o modalitate de a construi o soluție bună (ruta în cazul nostru), dar avem o modalitate de a cunoaște dacă o rută este bună sau nu (prin însumarea distanțelor dintre orașe, spre exemplu).
Abordările de Învățare Automată (Machine Learning)
Spre deosebire de problemele de optimizare, învățarea automată abordează o problematică foarte diferită. De exemplu, s-ar putea să dorim să învățăm software-ul să citească (recunoașterea optică a caracterelor, o problemă clasică de clasificare) sau să creăm un software care să poată filtra spamul în timp ce evoluează împreună cu creativitatea spamului sau chiar să folosească date istorice pentru a prezice congestionarea traficului care s-ar putea întâmpla mâine la prânz pe un anumit bulevard.
Pentru ca acest lucru să se întâmple, software-ul trebuie să ghicească relația dintre intrări și ieșire. Una dintre multele abordări este utilizarea rețelelor neuronale artificiale (ANN), care sunt o copie de bază la nivelul comportamental, a creierului uman. Neuronii și sinapsele (conexiunile între neuroni) sunt simulate într-un mod algoritmic și simulează modul în care creierul învață. Învățarea se numește instruire (training) și aceasta pregătește rețeaua pentru aplicația specifică pe care inginerul o construiește.
Cel mai mare avantaj al acestei abordări este capacitatea modelului rezultat de a generaliza. Aceasta înseamnă că, dacă îl instruiți pe unele date care descriu în mod relevant o problemă, modelul rezultat va putea aplica aceleași cunoștințe pentru alte date care vor fi prezentate intrărilor sale (desigur, cu o anumită acuratețe).
Concluzie
Inteligența artificială este mai mult decât doar computere care înțeleg ceea ce le spunem sau care îndeplinesc sarcini în mod inteligent. Există probleme grele pentru care nu avem încă algoritmi specializați sau, dacă avem, acești algoritmi sunt foarte lenți (cum ar fi Backtracking, o abordare a forței brute). În unele cazuri, abordările AI pot accelera rezolvarea problemelor sau pot oferi modalități de a le rezolva, indiferent cât de complexă este problema. Desigur, inginerii buni sunt o necesitate, deoarece proiectarea și implementarea unor astfel de sisteme necesită o atenție deosebită și cunoștințe intensive.
Holisun poate ajuta la proiectarea sistemelor complete de inteligență artificială, sau poate oferi asistență în proiectarea algoritmilor și a sistemelor pentru toate aceste tipuri de algoritmi. Expertiza acumulată de echipa Holisun de-a lungul anilor cuprinde ambele tipuri de abordări AI: Optimizări evolutive, precum și abordări de învățare automată. Interacțiunile hardware-AI sunt, de asemenea, domenii de studiu pentru noi, avem mai multe proiecte care abordează acest subiect, cum ar fi proiectul nostru de cercetare MUSHNOMICS sau proiectul de cercetare GOHYDRO.