")
")
What is Big Data? Unlike the name might suggest, it’s not about files that are really big, or a complete knowledge about something. But, in order to better grasp the meaning of this important term, first let’s try to understand what exactly is Data and how can it be BIG.
What is Data?
Unlike information, that can imply understanding, data can be regarded as a measurement of something, a value that describes the state at a certain point in time, without any information about how high or low that value is. So, information could be regarded as a comparison of data over a period of time.
Let’s take a temperature sensor, for example. If we place it inside an unknown environment and it reads 32°C, this is a data point, or a piece of data. But what can we learn about this data point? At the moment nothing. We do not have something to compare it to, in order to extract information. We do not know what the environment is, what are the high’s and low’s in that environment, what is the expected median value for the temperature, and so on.
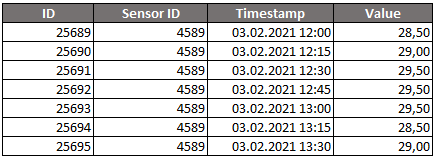
In order for us to be able to extract information about the environment itself, we must use many sensors and must collect many data points. The number of data points per unit of time is called the resolution, and this aspect is very important, as for certain applications we might need a certain resolution that is high enough so the environment reveals itself fully.
What is BIG Data?
Imagine reading sensors data in a greenhouse. To better understand the growth conditions for the plants, many sensors are needed, like temperature, humidity, light and so on. Let’s say we have 20 sensors.
We are interested in the daily variation for all the sensors, so a 15-minute reading resolution should be ok. This means 96 data points per sensor, so a total of 1920 data points will be generated daily. Yearly, the size of the database grows with an additional 700.000 data points. The volume is already overwhelming and is poised to grow exponentially as time passes. This is Big Data.
Why is Big Data important today?
We live in a world of information and are surrounded by countless systems that generate many petabytes of data daily. Collecting and analyzing this data is extremely important in the context of optimizations that can be applied on systems, but also for other purposes like fault detection, cybersecurity, intrusion/fraud detection and many more.
Conclusion
An important aspect to be noted is that Big Data is not limited to the Internet of Things (IoT) world, but has many applications in other areas too, like banking. Huge volumes of data are generated by every system daily. Why not use this data to inspect, debug and optimize such systems?
Holisun can provide Data Mining methodologies and complete workflows that enable Big Data to be analyzed, summarized and even generate Machine Learning models based on them. This can enable Digital Twin creation and full system analysis and predictions to happen. Big Data approaches are implemented in some of our projects, like BIECO, MUSHNOMICS and SDK4ED.