")
")
Machine Learning is an application of artificial intelligence that allows computer systems to automatically improve their performance by learning from data. It's similar to how humans learn: by experience and observation. The more data a machine learning model is exposed to, the better its performance will be.
Data Mining, on the other hand, is the process of discovering patterns and relationships in large datasets. This involves using statistical techniques and algorithms to analyze data and extract useful information from it. Essentially, data mining is like panning for gold - you sift through a lot of sand and rocks to find the valuable pieces.
Machine learning and data mining are often used together. Data mining can be seen as the first step in the process, where large amounts of raw data are analyzed to identify patterns and relationships. Machine learning then takes these findings and uses them to improve performance or make predictions. For example, a machine learning model might use data mined from customer purchases to predict what products a customer is likely to buy next.
In conclusion, machine learning and data mining are powerful tools that can help businesses and organizations make more informed decisions. By analyzing large amounts of data, these techniques can reveal hidden patterns and relationships that could be missed by human observation alone. As technology continues to evolve, we'll likely see even more advanced applications of machine learning and data mining in the future.
Have you ever noticed that sometimes it takes a long time for your computer or phone to load a website or an app? That's because the data has to travel from your device to a faraway server, where it's processed and then sent back to your device.
What is Edge-Fog-Cloud?
Edge-Fog-Cloud Computing is a new way of processing data that helps to make this process faster and more efficient. It works by dividing up the computing work between different layers: the "edge" layer is the devices that are closest to you, like your phone or your smartwatch. The "fog" layer is made up of nearby computers or servers that can help with processing the data. And the "cloud" layer is a group of servers that are far away but have lots of power to process data.
By dividing up the work in this way, Edge-Fog-Cloud Computing can make apps and websites load faster because the data doesn't have to travel as far. It also makes it easier to process large amounts of data in real-time, which can be useful for things like self-driving cars or smart homes.
In brief, Edge-Fog-Cloud Computing is a new way of processing data that can make our devices faster and more efficient, and it's something that we'll likely see more of in the future!
How does Edge-Fog-Cloud Computing work?
To be more specific, Edge-Fog-Cloud Computing is a new paradigm in computing that has emerged in recent years. It is a distributed computing model that combines the strengths of three different computing models: Edge Computing, Fog Computing, and Cloud Computing. This approach is designed to help organizations better manage the increasing amounts of data generated by devices and systems while addressing issues such as latency, security, and privacy.
The goal of Edge-Fog-Cloud Computing is to provide a distributed computing architecture that can efficiently handle large-scale data processing and analysis. In this model, computing tasks are distributed across multiple layers, from edge devices to fog nodes to cloud servers. By combining the strengths of these three computing models, Edge-Fog-Cloud Computing provides a flexible, scalable, and cost-effective approach to computing that can help organizations achieve their business goals more efficiently.
In the next sections, we will explain each of the three components of Edge-Fog-Cloud Computing in more detail.
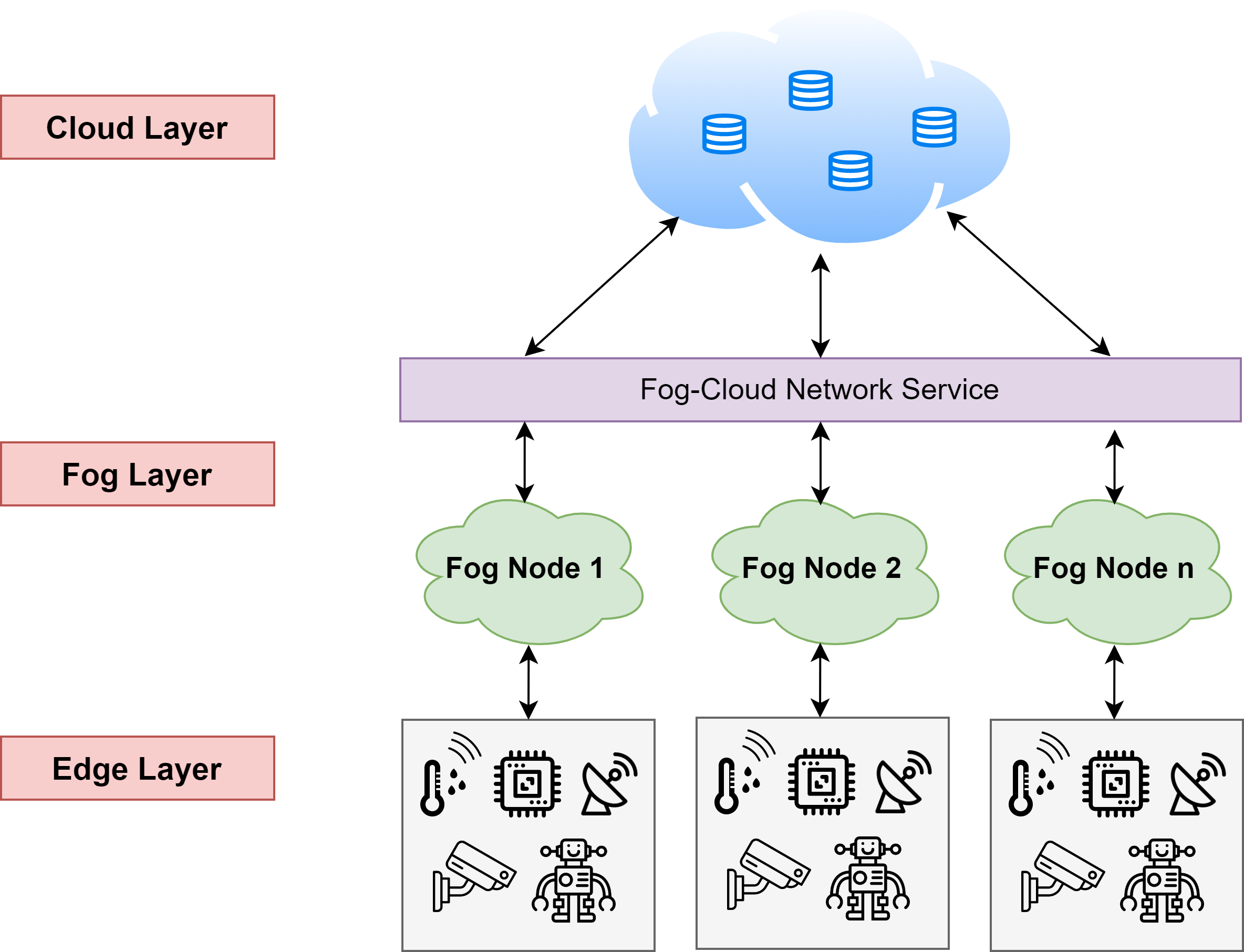
Edge-Fog-Cloud Architecture
1.Edge Computing:
Edge computing refers to the use of computing resources and services that are located closer to the end-user or device. This is in contrast to traditional cloud computing, where all computing is done in centralized data centers. With edge computing, processing is done on devices like smartphones, IoT devices, or network routers, which are located closer to the data source. This allows for faster processing and reduces the latency associated with sending data to a centralized cloud. Edge computing is particularly useful for applications that require real-time processing and analysis of data, such as in industrial IoT or autonomous vehicles.
2. Fog Computing:
Fog computing extends edge computing by creating a hierarchy of computing resources that provides more processing power and storage capacity. Fog nodes are intermediate points between edge devices and cloud servers that can provide additional processing and storage capabilities. These nodes can be located in nearby network equipment or at the edge of the network, closer to the end-user. Fog computing can help to reduce latency, improve security, and provide greater scalability and flexibility in computing resources.
3. Cloud Computing:
Cloud computing refers to the use of remote servers to store, manage, and process data. Cloud computing provides virtually limitless storage and computing resources that can be accessed from anywhere with an internet connection. Cloud servers are typically located in data centers that are far away from the end-user. Cloud computing is particularly useful for applications that require large-scale data processing and analysis, such as big data analytics or machine learning.
Conclusion
By combining these three computing models, Edge-Fog-Cloud Computing provides a distributed computing architecture that can efficiently handle large-scale data processing and analysis. In this model, computing tasks are distributed across multiple layers, from edge devices to fog nodes to cloud servers. This approach allows for faster processing of data, reduced latency, and improved reliability.
Overall, Edge-Fog-Cloud Computing provides a flexible, scalable, and cost-effective approach to computing that can help organizations achieve their business goals more efficiently.
What is Big Data? Unlike the name might suggest, it’s not about files that are really big, or a complete knowledge about something. But, in order to better grasp the meaning of this important term, first let’s try to understand what exactly is Data and how can it be BIG.
What is Data?
Unlike information, that can imply understanding, data can be regarded as a measurement of something, a value that describes the state at a certain point in time, without any information about how high or low that value is. So, information could be regarded as a comparison of data over a period of time.
Let’s take a temperature sensor, for example. If we place it inside an unknown environment and it reads 32°C, this is a data point, or a piece of data. But what can we learn about this data point? At the moment nothing. We do not have something to compare it to, in order to extract information. We do not know what the environment is, what are the high’s and low’s in that environment, what is the expected median value for the temperature, and so on.
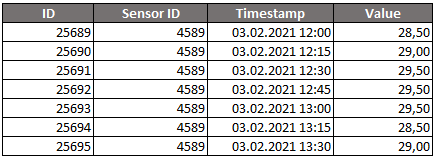
In order for us to be able to extract information about the environment itself, we must use many sensors and must collect many data points. The number of data points per unit of time is called the resolution, and this aspect is very important, as for certain applications we might need a certain resolution that is high enough so the environment reveals itself fully.
What is BIG Data?
Imagine reading sensors data in a greenhouse. To better understand the growth conditions for the plants, many sensors are needed, like temperature, humidity, light and so on. Let’s say we have 20 sensors.
We are interested in the daily variation for all the sensors, so a 15-minute reading resolution should be ok. This means 96 data points per sensor, so a total of 1920 data points will be generated daily. Yearly, the size of the database grows with an additional 700.000 data points. The volume is already overwhelming and is poised to grow exponentially as time passes. This is Big Data.
Why is Big Data important today?
We live in a world of information and are surrounded by countless systems that generate many petabytes of data daily. Collecting and analyzing this data is extremely important in the context of optimizations that can be applied on systems, but also for other purposes like fault detection, cybersecurity, intrusion/fraud detection and many more.
Conclusion
An important aspect to be noted is that Big Data is not limited to the Internet of Things (IoT) world, but has many applications in other areas too, like banking. Huge volumes of data are generated by every system daily. Why not use this data to inspect, debug and optimize such systems?
Holisun can provide Data Mining methodologies and complete workflows that enable Big Data to be analyzed, summarized and even generate Machine Learning models based on them. This can enable Digital Twin creation and full system analysis and predictions to happen. Big Data approaches are implemented in some of our projects, like BIECO, MUSHNOMICS and SDK4ED.
Throughout the history, intelligence was defined in many ways: the ability to do math, to solve problems, understanding communication, self-awareness, the ability to learn, and so on, at first in the effort to establish the difference between humans and animals (intelligence being one of the main differences), and later in order to understand life as a whole.
Our current understanding of intelligence can be described as the ability to perceive information, to retain knowledge and even apply it for behavior adaptation (https://en.wikipedia.org/wiki/Intelligence). In this sense, all known life is intelligent, as adaptations to available environments meant changing behavior in order to survive.
Artificial Intelligence (or AI), on the other hand, has vastly different applications. Throughout the still short history of the IT world, computer scientists have started to develop algorithms for hard mathematical problems, for which an established algorithm has not been designed yet. Thus, generalized approaches have come to the rescue.
Types of problems
In math, we have three elements that define a completely solved problem: the input, the objective function or some way of computing output based on the input values, and the output itself (see image below).

In the AI world, we have two types of problems, which need to be solved in some way:
- Problems for which we know the outputs and the inputs but we don’t know how to calculate the outputs based on the inputs (regression class problems, classification and so on).
- Problems for which we know the inputs and the objective function (a way to estimate the fitness of a proposed solution), and we want to optimize the input parameters in order to get the best outputs (TSP/VRP class and many other).
Taking inspiration from nature, there are two main algorithmic approaches, one for each type of problem:
- Evolutionary algorithms, that use concepts like evolution but also animal-world-approaches like the behaviour of ant colonies or bees in order to optimize different functions.
- Machine Learning approaches, that "learn" the data and come up with a way of computing the outputs based on the input.
Evolutionary Optimization, Genetic Algorithms
From the optimizations world, one of the best known class of algorithms are the evolutionary ones, and especially the Genetic Algorithms (GA) class. GA's use the principles of evolution, formulated by Darwin (but also with the latest observations made by biology experts), in order to generate (at least) a viable solution and then optimize it (improve a certain performance indicator). We can apply such algorithms in problems where we have the inputs, we have a way of knowing if a solution is good or not, but we do not have a way of computing the best solution.
For example, let's study a Travelling Salesman Problem (TSP). A salesman wants to visit a bunch of cities, while keeping the costs as low as possible. In order for this to happen, the salesman needs a route. A route can be defined as the order in which the cities must be visited. The best route is this order of cities that results in the smallest cost, where the cost can be time, money, distance, whatever we are interested in.
In a GA implementation, each possible (or candidate) route is called an individual. Each city is a Gene inside the individual's Chromosome, the order of the genes representing the final route. The algorithm works by creating a population of individuals and applying a set of operators: Selection, Crossover and Mutation. Recently, other aspects are being considered as operators, like: Survival, Inbreeding, Monogamy, etc.
As intuition might tell you, evolutionary algorithms work by gradually changing parts of individuals in a pool of solutions, in order to see if the results are better. Thus, we do not have a way of constructing the best route, but we do have a way of knowing if the route is good (by summing the costs between cities).
Machine Learning Approaches
In contrast with optimization problems, machine learning approaches a vastly different problem area. For instance we might want to teach software how to read (Optical Character Recognition, a classic clasification problem), or create a piece of software that can filter spam while also evolving together with the spammer's creativity, or even use historic data in order to predict the traffic congestion that might happen tomorow at noon.
In order for this to happen, the software piece has to guess the relationship between the inputs and the output. One of many approaches is to use Artifficial Neural Networks (ANN), that are a basic copy at the behaviour level, of the human brain. Neurons and synapses (connections between neurons) are simulated in an algorithmic fashion and simulate the way the brain learns. Learning is called training and this prepares the ANN for the specific application that the engineer builds.
The biggest advantage of this approach is the ML model's ability to generalize. This means that if you train it on some data that relevantly describes a problem, the ML model will be able to apply the same knowledge for other data that will be presented to its inputs (of course, with a certain accuracy).
Conclusion
Artifficial Intelligence is more than just computers understanding what we say to them, or performing tasks intelligently. There are hard problems for which we do not yet have specialized algorithms, or, if we do have, those algorithms are very slow (like Backtracking, a Brute Force approach). In some cases, AI approaches can speed up problem solving, or provide ways to solve them, no matter how complex the problem is. Of course, good engineers are a must, as designing and implementing such systems require great care and intensive knowledge.
Holisun can either help designing complete systems or offer assistance into algorithm and system design for all these kinds of algorithms. The knwoledge landscape that the Holisun team has gathered throughout the years encompases both kinds of AI approaches: Evolutionary Optimizations as well as Machine Learning approaches. Hardware to AI interactions are also fields of study for us, we have multiple projects that tackle this subject, like our MUSNOMICS Research Project, or GOHYDRO Research Project.